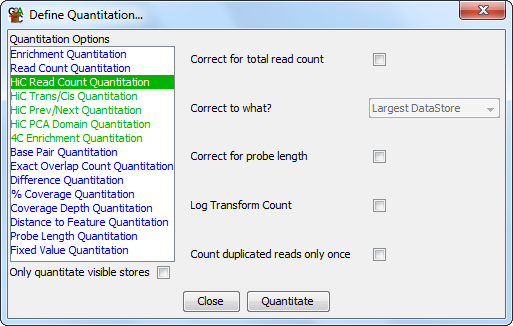
The HiC Read Count quantitation is a simple way to look at the HiC coverage in a set of probes. It works very much like the normal read count quantitation, except that it counts at the level of HiC read pairs. Any HiC read pair with one end overlapping the current probe will be counted in the quantitation, but pairs where both ends fall into the same probe will only be counted once.
The options you have for this module are:
If you choose to quantitate your data on a log scale then any probes which contain no reads will have their initial read count increased to 0.9 reads to avoid problems with infinite values when log transforming. This value is set before any subsequent correction for total read count or probe size. This means that in log transformed data different data stores could end up with different absolute values for probes containing no reads. If probe length correction is applied then probes with no reads will end up with a range of low values reflecting the different lengths of the probes. In these cases you might want to use an initial linear quantitation to allow you to flag and possibly filter out the regions with no reads, before later moving on to quantitate on a log scale.